Facebook, Cambridge Analytica, and the Economics of Privacy
By Cactusman
Facebook, Cambridge Analytica, and the Economics of Privacy
Cambridge Analytica – the data firm that provided consulting services for the Trump Campaign – has come under intense scrutiny for the firm’s capture and exploitation of vast quantities of user data from Facebook. These practices have added new urgency to questions about how information is collected online and how to protect users’ privacy rights.
From The New York Times:
“The firm had secured a $15 million investment from Robert Mercer, the wealthy Republican donor, and wooed his political adviser, Stephen K. Bannon, with the promise of tools that could identify the personalities of American voters and influence their behavior. But it did not have the data to make its new products work.
So the firm harvested private information from the Facebook profiles of more than 50 million users without their permission, according to former Cambridge employees, associates and documents, making it one of the largest data leaks in the social network’s history. The breach allowed the company to exploit the private social media activity of a huge swath of the American electorate, developing techniques that underpinned its work on President Trump’s campaign in 2016.”
In response, Facebook suspended Cambridge Analytica and several other involved parties. But an online statement from Facebook’s Deputy General Counsel Paul Grewal denied what happened constitutes a breach: “People knowingly provided their information, no systems were infiltrated, and no passwords or sensitive pieces of information were stolen or hacked.”
As Grewal details, this breach-without-a-breach ensued when an app developer, Dr. Aleksandr Kogan, used his “thisisyourdigitallife” personality app to collect data from a large pool of Facebook users and their connected friends. Dr. Kogan didn’t actually violate any Facebook policy until he passed that data to Cambridge Analytica and another company, Eunoia Technologies. The goal of all this data harvesting and sharing? To create psychographic models of American voters and use those models to tailor political messages in support of electing Donald Trump to the presidency.
As the story snowballs, new details continue to surface, such as Cambridge Analytica’s CEO being taped boasting about using sex workers to entrap and blackmail politicians, along with speculation on whether Facebook can be trusted with personal information. (This seems like an obvious ‘no.’)
Given this incident is but one of many major privacy breaches in recent memory, one question seems particularly relevant: why don’t we place higher value on our personal information and privacy?
First, let’s examine the fundamentals of the economics of privacy. Much of the research on this topic treats privacy information as a resource, proposes models for pricing this information, and seeks to create the right framework for a privacy market. On the face of it, this seems like a straightforward proposition; why shouldn’t private information be commoditized and used for commercial purposes?
Because people don’t know how to value their privacy or safeguard it. One particular challenge to a market-based approach to privacy is sorting out the incongruity between peoples’ expressed attitudes about the value of their privacy and their actual willingness to forfeit it. This discrepancy – referred to as the “privacy paradox” – is readily apparent in privacy surveys. The following chart from the Pew Research Center, for example, shows that large majorities of respondents say it’s important to be in control of who can get information about them and what information is collected.
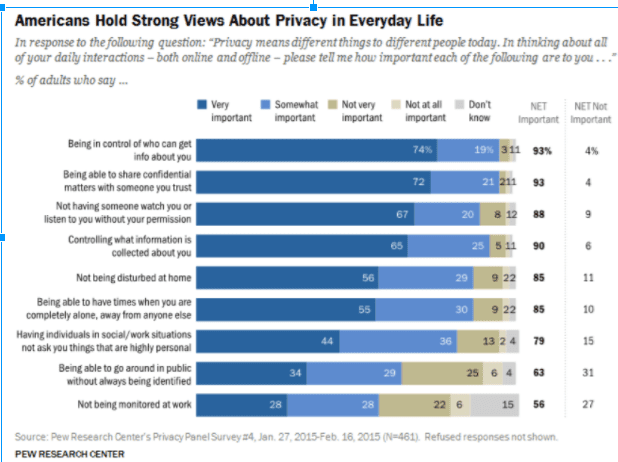
Despite these strong professed attitudes about privacy, however, social media use has risen significantly among American adults as shown below:
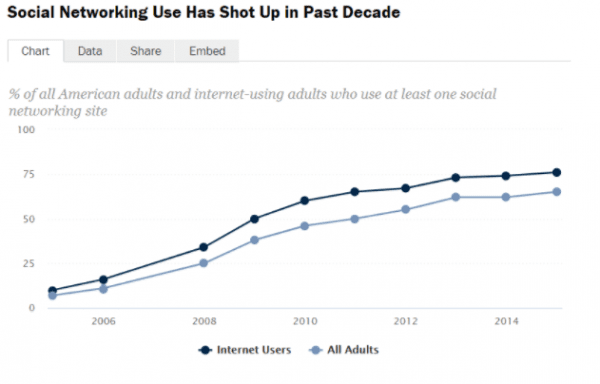
This privacy paradox comes in many forms, but the way it’s manifested in social media – with users having little regard for all the personal information being collected – is particularly interesting. For corporations who trade in data, the response is predictable: users agree to our terms of service and are getting all our great services for free. But, of course, those services are not free at all, and the divergence between individuals’ stated preference and behavior is an indicator that they are failing to accurately price the value of their personal information.
Flaws in the terms-of-service argument have surfaced before. In 2014, for example, Facebook came under scrutiny when an experiment surfaced that many also saw as a breach of users’ privacy rights. The experiment, which took place for a week in 2012, involved altering users’ news feeds to perform A/B testing. Researchers embedded positive and negative language in the feeds and then monitored the effect on users’ emotional states. When the study came to light, many saw it as manipulative and underhanded and were outraged that the company had hidden the legal cover in its (extremely long) terms of service.
In a UCLA Law Review article, Chris Hoofnagle and Jan Whittington sum up the problem:
“Despite lengthy and growing terms of service and privacy, consumers enter into trade with online firms with practically no information meaningful enough to provide the consumer with either ex ante or ex post bargaining power. In contrast, the firm is aware of its cost structure, technically savvy, often motivated by the high-powered incentives of stock values, and adept at structuring the deal so that more financially valuable assets are procured from consumers than consumers would prefer.”
With such substantial information asymmetries in place, how could individuals be expected to fully understand the implications of their decision to “check the box” and agree to a platform’s terms of service?
But the privacy-value problem extends beyond availability of information and into the behavioral realm. One study, for example, looked at whether providing users more control would, in fact, help them reduce their risk of exposing sensitive information. Surveys were set up to emulate social network privacy controls by allowing participants to choose options such as which questions to answer and whether to allow researchers permission to publish their answers. In a series experiments, participants were given increasing amounts of control over their information. The results revealed what the researchers called a “control paradox:” participants with the highest levels of control actually exposed the most information about themselves.
Beyond our inability to effectively use privacy controls, individuals also have a tendency to discount their personal risk of being affected by a privacy breach. This misperception, known as optimism bias, was documented using a phone survey that asked participants to rate their own likelihood and that of others to having their information stolen or misused. On a scale of 1 to 7, with 7 indicating the highest level of risk, participants rated their perceived risk a full point lower than they rated the risk of “other people.”
Contemplating these, and many other, problematic findings on our behavioral attitudes to privacy information, it’s clear that even correcting the information and bargaining asymmetries won’t be enough to create a functioning privacy market. Considering what happened with Facebook and Cambridge Analytica, the element of control was already in place (no one was required to use Dr. Kogan’s “thisisyourdigitallife” app). And the research indicates that even if Facebook had plastered a huge red label that read “this app allows your private Facebook data to be collected,” many people still would have used it.
Any proposed solution, therefore, needs to recognize how easy it is for companies to use their online platforms to spy on and manipulate users. It also needs to consider how we, on average, are terrible at weighing privacy risks and using controls to manage our information effectively. Helping us set a value for our personal information, then, isn’t enough. But, similar to regulation of public health risks such as smoking and seat belt use, we need protection from our own poor judgement.
Good discussion. Let me just provide the shorter Paul Grewal – “what we did was perfectly legal”, No sense of ethics or accountability whatsoever.
Still waiting for all those dopes who called for war with Russia over “interference” starting demanding that Wastebook be RICOed and run out of business. They’re so dumb they are probably STILL posting BS Russian election meddling stories on their Wastebook pages while Zuckershmuck keeps laughing and collecting their data.
Putin no doubt sees what bin Laden saw–the best way to “destroy” America is to give us a little nudge, and then in our hubris, ignorance arrogance we’ll do 1,000 times more damage to ourselves than our adversaries could ever hope to do.
“Helping us set a value for our personal information, then, isn’t enough.”
I agree with that.
“But, similar to regulation of public health risks such as smoking and seat belt use, we need protection from our own poor judgement.”
Yeah, but there’s that individual freedoms’ thing. The right wing and most of the right side of the isle is still and always has been vehemently opposed to curtailing them, which states with dominating GOP cultures oppose and with states rights “protection from our own poor judgment,”, while I agree it’s needed, aiin’t within the realm of reality.
Dream on…
Put anything on FB and just consider it public data. Yes people are going to examine it and try to sell you products, services, ideas, candidates, whatever. Just accept it as the deal and either use FB or don’t. Cambridge Analytica performed a valuable service for millions of people in reality as did others who try to connect with what they think FB users might want.